目標
本章最後會玩成一個仿生態系進化的模擬遊戲,使用者在棋盤上某些位置放置生物後,觀察是否能繼續繁衍下去。會學到的東西有:
- 以 C/C++ 觀點了解記憶體的總類和特性
- pass-by-value / pass-by-address / pass-by-reference
- for-loop
- 標頭檔 (header file) 的使用
- make 的使用
記憶體的分類與使用情境
- Register – 很快速,很貴,CPU 做計算時直接使用的記憶體。
- Stack – 普通快,普通貴,FIFO、存放執行檔的記憶體。
- Heap – 便宜,空間大的記憶體。
以下面這個小程式來說
int main()
{
int a, b, c;
c = a + b;
return 0;
}
他會被 compiler 轉換成類似下面的組語,然後在執行時連同指令部分 (.text) 和資料部分 (.data) 一起被丟到 stack memory 中。
pseudo-code
section .text
MOV R1, a
MOV R2, b
ADD R1, R2
MOV C, R1
section .data
a: .dword
b: .dword
c: .dword
- 將 a 記憶體內的資料放入編號 R1 的暫存器
- 將 b 記憶體內的資料放入編號 R2 的暫存器
- 將暫存器 R1 和 R2 加起來,結果會放在 R1 裡面
- 將 R1 的資料再放回 c 的記憶體位置
Stack 內的指令區和資料區和 CPU 暫存區的示意圖如下:
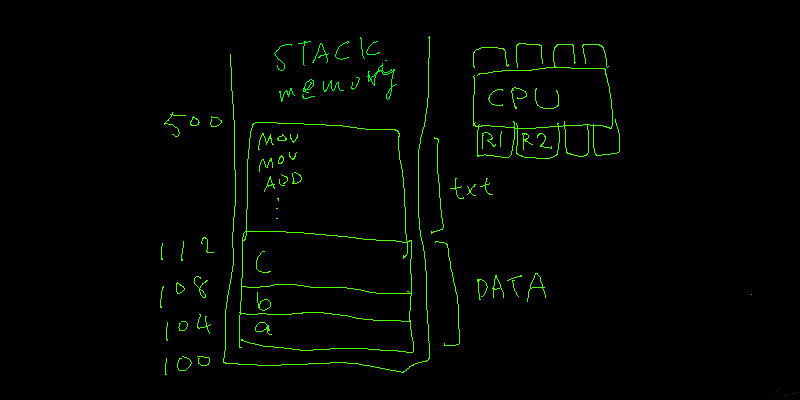
Function in Stack
除了 main function,每次在呼叫一個新的 sub function 時,sub function 也會堆疊在 stack 之中,等到 function 結束時就移除。Stack 的大小是有限的,所以常見的當機問題是呼叫過多的 function,或是某個 function 裡面宣告了太多與太大的資料,就會造成 stack overflow 導致當機。所以在 function 中不該放入過大的變數,重複的工作需要用 function 來處理,與 recursive function 的邏輯正確 ,這些都是避免 stack overflow 要注意的地方。
參考下面的程式
void sub_function( int a )
{
a = 4;
}
int main()
{
int a = 5;
sub_function( a );
return 0;
}
字面上看來,main 丟了一個整數 a,然後 sub_function 將 a 改成 4。但實際上的運作如下
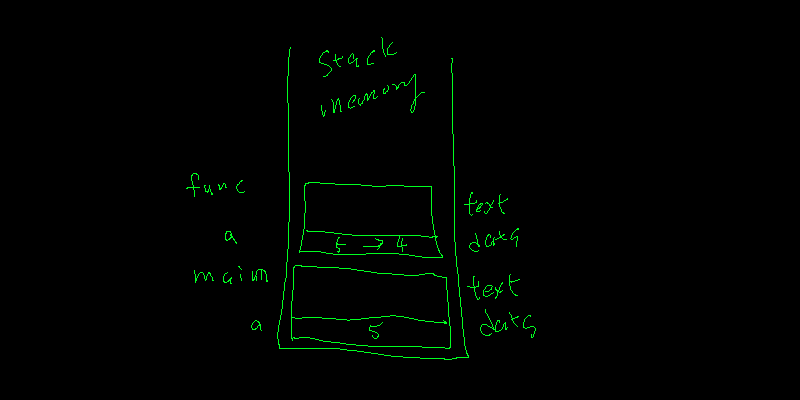
- 呼叫 sub_function 時,在 stack memory 內產生了一個新的 text / data 區塊,sub_function 的 data section 有一個整數的記憶體取名為 a,裡面放了從 main 的 a 中複製過來的數值 5。
- sub_function 將自己 data section 的數值從 5 改成 4。
- sub_function 結束且釋放使用的 stack memory
main 裡面的 a 從頭到尾都沒有變更過,一直都是 5。這種流程我們稱作 pass-by-value。
所以,如果我們希望 sub_function 更改變數 a 的數值,必須用另一種方法。
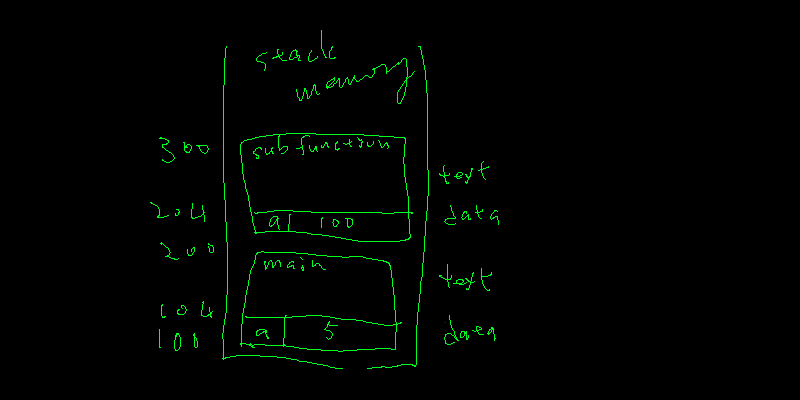
- 呼叫 sub_function 時,在 stack memory 內產生了一個新的 text / data 區塊,sub_function 的 data section 有一個整數的記憶體取名為 a,裡面放了從 main 的 a 的記憶位置 (address: 100)。
- sub_function 有了 main 的 a 變數的 address,就可以直接對該記憶體作更改了。
在 C/C++ 中,我們用下面程式的寫法來表示上面的流程。
void sub_function( int* b )
{
*b = 4;
}
int main()
{
int a = 5;
sub_function( &a );
return 0
}- &a 是 a 的 address
- int* b 意指 b 是用來放某個整數的變數的記憶體位置用的
- *b = 4 是 b 的記憶體位置指向的變數 (也就是 a)
所以 sub_function 要求的是一個整數的記憶體位置,且在裡面對該記憶體位置代表的變數值直接作修改。這樣直接修改變數的作法叫作 pass-by-address 。
pass-by-value 和 pass-by-address 其實就可以做到所有事了,但是有人認為一堆星號或 AND 符號很難讀懂,且容易出錯,所以 C++ 引進了一種叫 pass-by-reference 的語法。請參考下面:
void sub_function( int& a )
{
a = 4;
}
void main()
{
int a = 5;
sub_function( a );
}
上面的程式跟 pass-by-address 的範例所作的事完全一樣,但是語法上隱藏了記憶體位置,看起來比較易讀,也不會有在 sub_function 內意外修改了 a 的 address 導致錯誤的可能。
陣列 array 與 for-loop
在上一章的井字遊戲,我們用了九個整數變數來代表九個格子。但是我捫這次要模擬的生態棋盤至少有 100 個格子,不可能再用之前的方法來處理,所以我們來介紹 array 與處理 array 一定會用到的 for-loop。
#include <iostream>
int main()
{
int board[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
for ( int index = 0; index < 10; index++ )
{
std::cout << board[index] << std::endl;
}
return 0;
}
注意: 陣列的 index 是從 0 開始,不是 1。
當程式宣告了 board 是十個整數的陣列時,程式會留下十個 “連續” 的整數空間。當我們說要 access 某個位置,像是 board[2] = 2 這種寫法時,board[2] 在 compile time 會轉換成 board 的記憶體位置加上二個 int 變數長度。為什麼我們需要知道這個? 因為單寫成 board 前後不加框號時,它代表的其實就是 memory address。
看下面的例子:
#include <iostream>
void sub_function( int *board )
{
board[1] = 500;
}
int main()
{
int board[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
sub_function( board );
for ( int index = 0; index < 10; index++ )
{
std::cout << board[index] << std::endl;
}
return 0;
}
sub_function 在上面的例子中,要求的是一個整數的記憶體位置,board 雖然是個陣列,但其實也就是一個 memory address 後面長度是十個 int,所以可以直接這樣寫。警告: 這是不好的寫法,sub_function 並不知道 board 有多大,如果 sub_function 意外的寫了 board[11] = 1 程式就會當機了。
陣列也可以寫成二維或更高維,對棋盤格子來說,二維平面是最方便使用的。
#include <iostream>
int main()
{
int board[2][3] = { { 1, 2, 3 },
{ 4, 5, 6 } };
for ( int i = 0; i < 2; i++ )
{
for ( int j = 0; j < 3; j ++ )
{
std::cout << board[i][j] << std::endl;
}
}
return 0;
}
但是 2d array 在 function 的傳遞上挺麻煩的,直接計算位置的方法是這樣:
#include <iostream>
void draw_world( int *board, int x_size, int y_size )
{
// draw the 2-dimension board
for ( int i = 0; i < x_size; i ++ )
{
for ( int j = 0; j < y_size; j ++ )
{
std::cout << ( *(board + i * y_size + j ));
}
}
}
int main()
{
const int x_size = 5;
const int y_size = 5;
int board[5][5] =
{
{ 1, 0, 0, 0, 1 },
{ 1, 1, 0, 0, 0 },
{ 0, 0, 0, 1, 0 },
{ 1, 0, 1, 1, 0 },
{ 0, 0, 1, 0 ,1 }
};
draw_world( (int*)board, x_size, y_size );
return 0;
}
- (int*) 是告訴 compiler 我們知道 board 本來應該是 int [5][5],但因為不得已請把它當成 (int*),其實二者都代表的是一個記憶體位置沒有差別的。
- const 指的是該變數永遠不會更改數值。
作業: 遞迴練習,完成下面的 function。
- 井字遊戲評分,某個棋盤狀態分數越高,贏面越大
- 若該棋盤贏了是一分,輸了是負一分
- 我們希望越早贏越好,所以加入 layer 概念,正數時越淺分數越高 (using weight)
- 我們希望越晚輸越好,所以加入 layer 概念,負數時越淺分數越低 (using weight)
- 若沒輸沒贏,則將所有可能走法遞迴呼叫下一層
- 修改井字遊戲,利用狀態分數判斷下一步要走哪步。
- 修改 weight,將 AI 調整到你最滿意的程度。
// 0 means empty, 1 means player, 2 means com
int get_score( int* board, int next_move, int layer )
{
int win_count = 0;
int winner;
// check if there is a winner
winner = check_winner( board );
if ( winner == 1 )
{
// TODO: for different layer, we should assign
// different weight because we want win as soon as possible
// and lose as later as possible
return 1;
}
else if ( winner == 2 )
{
// TODO: for different layer, we should assign
// different weight because we want win as soon as possible
// and lose as later as possible
return -1;
}
// for each possible move, new_board
{
int next_next_move;
if ( next_move == 1 )
next_next_move = 2;
else
next_next_move = 1;
int score = get_score( new_board, next_next_move, layer + 1 );
win_count = win_count + score;
}
return win_count;
}
Heap 的使用
開頭有講 memory 分三種,但一直沒提到第三種 heap。heap 和 stack 不同,它不是堆疊的。記憶體在取得和釋放時不用遵守 FIFO。因為 heap 便宜用大塊,所以如果程式需要一塊大的記憶體時,盡量不要使用 stack。
使用 Heap 的方法如下:
#include <iostream>
void sub_function( int* address )
{
std::cout << *address << std::endl;
}
int main()
{
int *single;
int *board;
single = new int;
board = new int[10];
*single = 5;
board[0] = 1;
sub_function( single );
sub_function( board );
delete single;
delete [] board;
return 0;
}
- 釋放 heap 時,單一變數和陣列的釋放方法不同。
- address 送到 function 裡面時,function 並不在乎也不知道其是否為陣列。
- 直接更改某個 address 內的值,與取得某個變數的位置的方法,請確定不要搞混二者。
如果要了一塊 heap 而忘了釋放,這種情況叫 memory leak,是很難除錯又很常發生的問題。C++11 有介紹一種 heap allocation 寫成物件的避免 memory leak 的東西叫 smart pointer,這非本章的範圍,我們會在物件章節再說。
… 補充
以下的寫法,不應該出現在物件導向風格的程式裡。Heap 記憶體的取得和釋放如果不是在同一個 function 內完成、就該在同一個物件的 constructor / destructor 內完成 (以後會詳述)。但是這種東西有時在面試時會當基礎問題來考,所以還是要理解。
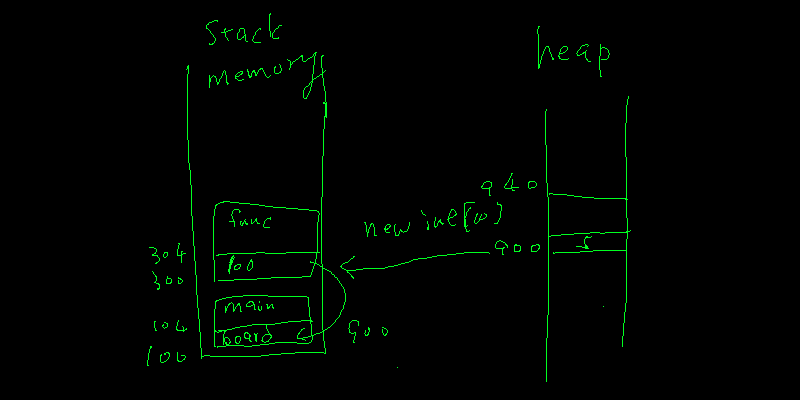
我們宣告了一個 int* board 的變數,board 這塊記憶體裡面裝的就是一個 address,&board 代表的就是裝這著 address 的記憶體位置,而在 function 變數中的 int** 就是一個記憶體位置變數的位置。搞這麼複雜是要做甚麼呢? 就是叫 function 幫忙取得一塊記憶體,然後提供給 board 來用。覺得太複雜建議拿張紙仿照上面的 stack 劃出圖來。
void sub_function( int** address )
{
*address = new int[10];
}
int main()
{
int *board;
sub_function( &board );
board[1] = 5;
delete [] board;
return 0;
}
作業 : 說明下面表格內的變數符號的各種意義,或是指出不存在的錯誤語法。
| * | & | ** | |
| Variable’s Type | int *a | int &a | int **a |
| Function Parameter | func( int *a ) | func( int &a ) | func( int **a ) |
| Variable’s Symbol | *a | &a | **a |
An example for **a
#include <iostream>
int main()
{
int a = 10;
int *b = &a;
int **c = &b;
std::cout << "a value: " << a << std::endl;
std::cout << "a address: " << &a << std::endl;
std::cout << "b value: " << b << std::endl;
std::cout << "b address: " << &b << std::endl;
std::cout << "c value: " << c << std::endl;
std::cout << "using c to access a: " << **c << std::endl;
return 0;
}
模擬生態圈
生物的特性,是如果周遭沒有其他生物時,會因為生物鏈無法維持而死亡。但如果生物周遭的生物數量過多,也會因為資源消耗過多導致滅絕。我們這次要作的作業就是模擬這樣的生態圈。
規則如下:
- 生物鄰近的格子,如果少於或等於二個生物,該生物在下世代將死亡。
- 空格子相鄰的格子的總生物數在三到四個之間,該格子將產生新的生物。
- 生物鄰近的格子,如果為三到六個生物,則該生物在下世代將繁衍。
- 生物鄰近的格子,如果多餘或等於七個生物,則該生物在下世代將死亡。
請修正以下的程式。
#include <iostream>
#include <string>
void draw_world( int *board, int x_size, int y_size )
{
// TODO: draw a good looking the 2-dimension board
for ( int i = 0; i < x_size; i ++ )
{
for ( int j = 0; j < y_size; j ++ )
{
std::cout << ( *(board + i * y_size + j ));
}
}
}
int next_slot( int* board, int x_size, int y_size , int x, int y )
{
// TODO: write this
// note: not all of them has 8 adjacent slots
return 0;
}
void next_gen( int* board, int x_size, int y_size )
{
// create a new board first
int* next_board = new int[ x_size * y_size ];
// draw the 2-dimension board
for ( int i = 0; i < x_size; i ++ )
{
for ( int j = 0; j < y_size; j ++ )
{
*(next_board + i * y_size + j ) =
next_slot( board, x_size, y_size, i, j );
}
}
// TODO: copy the next_board back to board
delete [] next_board;
}
int main()
{
const int x_size = 5;
const int y_size = 5;
std::string input;
int board[5][5] =
{
{ 1, 0, 0, 0, 1 },
{ 1, 1, 0, 0, 0 },
{ 0, 0, 0, 1, 0 },
{ 1, 0, 1, 1, 0 },
{ 0, 0, 1, 0 ,1 }
};
draw_world( (int*)board, x_size, y_size );
std::cout << std::endl << "continue? \"y/n\"" << std::endl;
std::cin >> input;
while ( input != "n" )
{
next_gen( (int*)board, x_size, y_size );
draw_world( (int*)board, x_size, y_size );
std::cout << "continue? \"y/n\" "; std::cin >> input;
}
return 0;
}
標頭檔
- 怎麼用?
- 為什麼要用?
在 C/C++ 中,function 必須要告知才能使用。但是語法上我們可以只告知 function 長的甚麼樣子 (也就是宣告) 就好,然後把 function 的實際運作邏輯寫在最後面,如下:
void func( int param );
int main()
{
return 0;
}
void func( int param )
{
return;
}
要注意,同一個 function 只能宣告一次,以下的程式將無法正確 compile
void func( int param );
void func( int param ); // compile error!
int main()
{
return 0;
}
void func( int param )
{
return;
}
我們可以把所有的宣告 放在其他的檔案,然後用 #include 要求 compiler 把某個檔案內的所有東西都崁入目前得程式碼中。
utility.hpp
#ifndef UTILITY_HPP
#define UTILITY_HPP
void func( int param );
#endif // end of UTILITY_HPP
main.cpp
#include "utility.hpp"
int main()
{
return 0;
}
void func( int param )
{
return;
}
那幾行 UTILITY_HPP 是為了防止同一個 function 被重複宣告,造成重複宣告錯誤用的。
最後,我們可以再把 function 的實作也放在不同的檔案。
utility.hpp
#ifndef UTILITY_HPP
#define UTILITY_HPP
void func( int param );
#endif // end of UTILITY_HPP
main.cpp
#include "utility.hpp"
int main()
{
return 0;
}
utility.cpp
#include "utility.hpp"
void func( int param )
{
return;
}
二個以上的 cpp 檔案時,我們先分別把他們編譯成 object file,然後再 link 起來。
- g++ -I./ -c utility.cpp
- g++ -I./ -c main.cpp
- g++ -I./ -o myapp utility.o main.o
Make
- 怎麼用?
- 為什麼要用?
上面的例子只有二個檔案,每次編譯都要打三行字,而且為了防止錯誤,從新編譯時還要先把舊的 utility.o 和 main.o 與 myapp 刪除,很是麻煩。Make 這工具就是幫忙把這些事寫在一個 batch 裡面一次做完。下面是一個簡單的例子
Makefile
all: compile_object link_object
compile_object:
g++ -I./ -c utility.cpp
g++ -I./ -c main.cpp
link_object:
g++ -I./ -o myapp utility.o main.o
clean:
@rm -rf utility.o
@rm -rf main.o
@rm -rf myapp
簡單說明,每件 “任務” 都是一個名字加上分號。真的執行某些任務時,前面的不是空格,而是 TAB。這裡面有一個叫 all 的任務,all 會先執行 compile_object 再執行 link_object。clean 是個獨立任務,工作只是刪除不用的檔案。使用時,就是再 Makefile 的檔案目錄下,打:
- make all (或簡寫成 make)
- make clean (要清理垃圾時)
Make 還定義了很多其他的工具,像是各種 macro 或是分拆主檔名和副檔名之類的功能。以下是某個小專案用的 makefile
CPP = g++
CPPFLAGS = -O3 -ansi -std=c++11 -pthread -Iinclude -L/usr/local/lib -lssl -lcrypto
VPATH = include \
src/error \
src/server \
src/world \
src/database \
src/memory
OBJDIR = obj
OBJS = $(addprefix $(OBJDIR)/, \
main.o \
ocerror.o \
coreserver.o \
rawprocessor.o \
cube.o \
player.o \
command.o \
world.o \
filedatabase.o \
event.o \
memleak.o \
mob.o \
)
TARGET = exe
# clear suffix list and set new one
.SUFFIXES:
.SUFFIXES: .cpp .o
# $@ is the target, i.e. ${TARGET}
${TARGET} : resources ${OBJS}
${CPP} ${OBJS} ${CPPFLAGS} ${INC} -o $@
# create folder if not exist
resources :
@mkdir -p $(OBJDIR)
# <$ is the first dependency, i.e. xxx.cpp
$(OBJDIR)/%.o : %.cpp
${CPP} $< ${CPPFLAGS} -c -o $@
# prevent there is a file named clean.cpp
.PHONY: clean
# prefix '@' is not to print the command to console
clean:
@rm -rf $(OBJDIR)
@rm -rf ${TARGET}
@rm -rf save
可以看出來它有從 object file name 取得 program file name 的功能,將 compiler 和 compile flag 抽出來寫成 macro,還有些路徑相關的 macro,不過基本的概念都是一樣的。
Other Notable Features for C
- Variable Scope
#include <iostream>
int myint = 1; // global scope
int main()
{
int myint = 2; // in main scope
if ( true )
{
int myint = 3; // in if scope
std::cout << "myint is: " << myint << std::endl;
}
return 0;
}
- C-Style String
#include <iostream>
int main()
{
char cstr[10] = { 'h', 'e', 'l', 'l', 'o', '\0', '\0', '\0', '\0', '\0' };
std::cout << cstr << std::endl;
return 0;
}- Struct
#include <iostream>
struct Point
{
int x;
int y;
int z;
};
int main()
{
struct Point point;
point.x = 10;
point.y = 12;
point.z = 14;
std::cout << "x:" << point.x << std::endl;
std::cout << "y:" << point.y << std::endl;
std::cout << "z:" << point.z << std::endl;
return 0;
}
- Standard C Library that Frequently Used
memory and c-string
#include <cstdio> // memory
#include <cstring> // strcpy
int main()
{
char cstr[10];
memset( (void*)cstr, 0, 10 ); // clean up memory
memcpy( (void*)cstr, "abcd", 4 ); // copy memory
strcpy( (char*)cstr, "abcd" ); // copy c string
return 0;
}
math
#include <cmath>
#include <iostream>
int main()
{
double result;
result = sin( 30.0 * 3.14159 / 180 );
std::cout << "sin(30degree): " << result << std::endl;
return 0;
}random number
#include <cstdlib> //rand()
#include <ctime> // time()
#include <iostream>
int main()
{
// using the same random seed
// the sequence of random number is always the same
std::cout << "random number - fix seed (1~100): " << (( rand() % 100 ) + 1) << std::endl;
// we use current second as the seed
srand(time(NULL));
std::cout << "random number - time seed (1~100): " << (( rand() % 100 ) + 1) << std::endl;
// NOTE! THIS RANDOM IS NOT GOOD ENOUGH FOR NETWORK SECURITY USAGE
return 0;
}
- Function Pointer (not necessary for C++ style programming)
- Function with Variable Parameters (not necessary for C++ style programming)